Acceleration technology inside FireDucks
SWITCHING GROUPBY
In this article, we introduce the acceleration techniques of “groupby” used in FireDucks.
The groupby operation is one of the most fundamental and important operations in tabular data analysis. We can use the groupby operation to obtain important statistical properties such as the mean and variance of the data. We can also combine it with other operations to obtain new features.
FireDucks optimizes based on data characteristics for fast groupby operations. One such optimization is the automatic selection of groupby algorithms based on the number of groups. FireDucks’ groupby algorithm focuses on the number of groups of data and switches between an algorithm that is fast for data with a small number of groups (Algorithm A) and an algorithm that is fast for data with a large number of groups (Algorithm B). The number of groups indicates the type of data that make up the target column.
Consider the following tabular data.
| food | category | |
|---|---|---|
| 0 | apple | fruit |
| 1 | carrot | vegetable |
| 2 | peach | fruit |
| 3 | onion | vegetable |
| 4 | grape | fruit |
There are five elements that make up the “food” column: “apple”, “carrot”, “peach”, “onion”, and “grape”. Therefore, the number of groups in the “food” column is 5. Next, we see that there are two types of elements that make up the “category” column: fruit and vegetable. Therefore, the number of groups in the “category” column is 2.
Calculating the number of groups for large data sets is time-consuming. Therefore, FireDucks uses a statistical method to estimate the number of groups without obtaining an exact value for the number of groups1. The estimation is performed as follows.
- Extracts a random piece of data from a sequence of data of interest.
- Record that data.
- Again, take out one data at random from the column of data of interest.
- That data is checked to see if it matches the recorded data and record.
- Repeat operations 3 and 4 multiple times.
After repeating operations 3 and 4 multiple times, FireDucks estimates the number of groups of data in the group key of interest from the number of times the data was retrieved and the number of matches.
Evaluation
We measured the calculation speed using TPC-H, a benchmark that includes many processes related to data analysis.
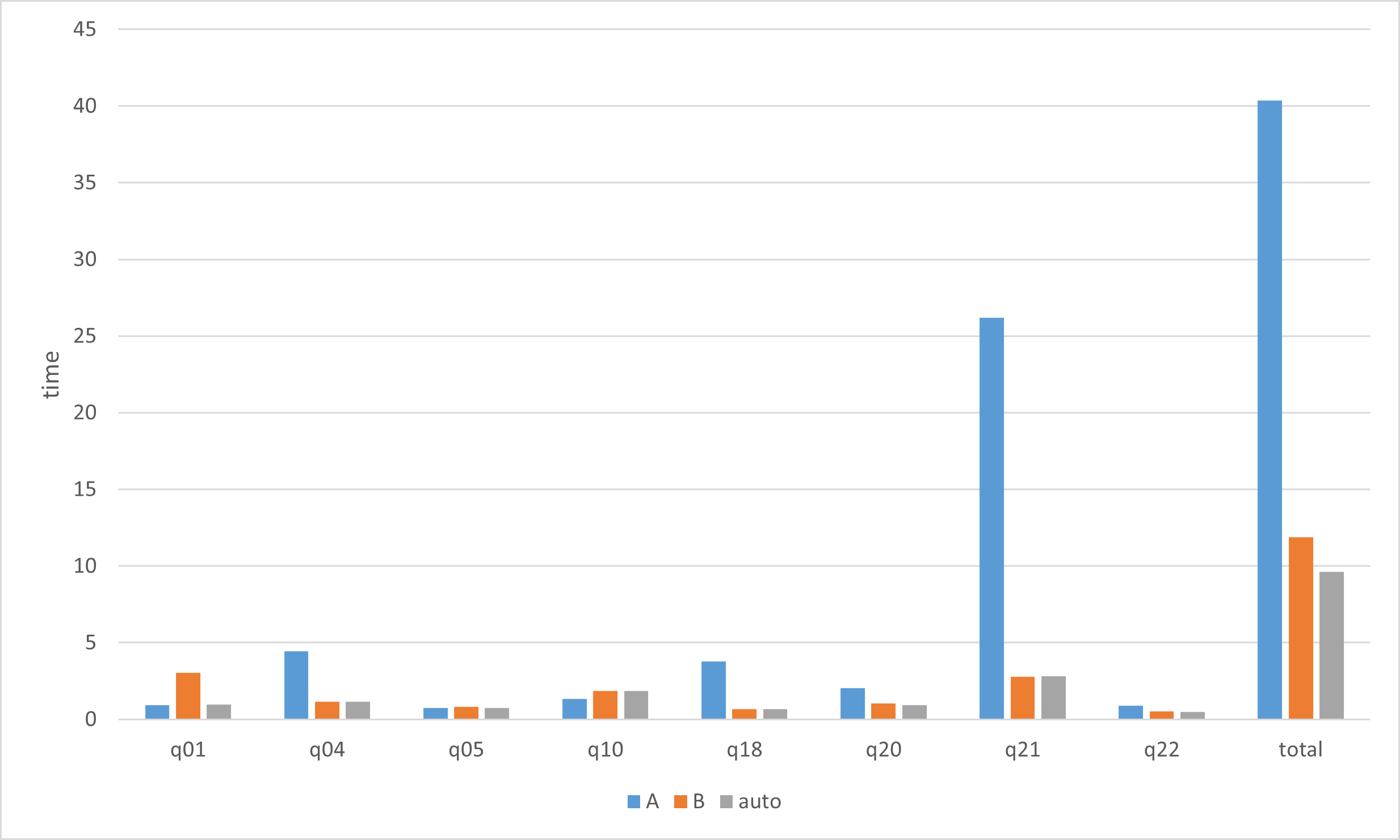
“A" uses only Algorithm A for groupby operations, and “B” uses only Algorithm B for groupby operations. “auto" estimates the number of groups and automatically selects between Algorithm A and B for the groupby operation.
Processes for which there is little difference in execution time between Algorithm A and Algorithm B are omitted from the above graph. The graph shows that, with the exception of q10, the automatic selection algorithm is the faster of Algorithm A and Algorithm B.
The total shows the computation time for the entire TPC-H, including the processes excluded from the above graph for Algorithm A, Algorithm B, and the automatic selection algorithm. This indicates that the automatic selection algorithm is about 3 times faster than Algorithm A, and about 1.2 times faster than Algorithm B for TPC-H as a whole.
Reference
M. Bressan, E. Peserico, and L. Pretto. Simple set cardinality estimation through random sampling. CoRR, abs/1512.07901, 2015. ↩︎