FireDucks内部で働く高速化技術
groupbyの切り替え
この記事ではFireDucks内部で使われているgroupby高速化技術について紹介します.
表データ分析においてgroupby操作は最も基本的で重要な操作の一つです. groupby操作を用いることでデータの平均や分散といった重要な統計的性質を知ることができ, その他操作と組み合わせることで新しい特徴量を得ることもできます.
FireDucksでは高速なgroupby操作を実現するためにデータ特性に応じた最適化を行っています. その一つがグループ数によるgroupbyアルゴリズムの自動選択です. 具体的にはデータのグループ数に注目しグループ数が小さいデータに対して高速に計算可能な アルゴリズム(アルゴリズムAと呼ぶ)と, グループ数が大きいデータに対して高速に計算可能なアルゴリズム(アルゴリズムBと呼ぶ)とを切り替えています. ここでグループ数とは注目するカラムを構成するデータの種類を示します.
例えば以下のような表データを考えてみましょう.
| food | category | |
|---|---|---|
| 0 | apple | fruit |
| 1 | carrot | vegetable |
| 2 | peach | fruit |
| 3 | onion | vegetable |
| 4 | grape | fruit |
foodカラムを構成する要素に注目するとapple, carrot, peach, onion, grapeの5種類であることが分かります. よってfoodカラムのグループ数は5です. 一方で,categoryカラムを構成する要素に注目するとfruit,vegetableの2種類であることが分かります. よってcategoryカラムのグループ数は2です.
グループ数の推定
巨大なデータを扱うときに実際にデータを全て確認してグループ数を計算すると時間がかかります. そこで,FireDucksではグループ数の厳密な値を求めることなく統計的手法を用いてグループ数の推定を行っています1. 具体的には以下の手順で行われます.
- 注目するグループキーのデータ列の中からランダムにデータを一つ取り出す.
- 取り出したデータを記録する.
- 再び注目するグループキーのデータ列の中からランダムにデータを一つ取り出す,
- すでに記録してあるデータと一致するか判定を行い,データを記録する.
- 3,4の操作を一定回数繰り返す.
3と4の操作を一定回数繰り返した後,データを取り出した回数と一致した回数から 注目するグループキーのデータのグループ数を推定する.
性能評価
データ分析に関する多くの処理を含むベンチマークであるTPC-Hを用いて計算速度の計測を行いました.
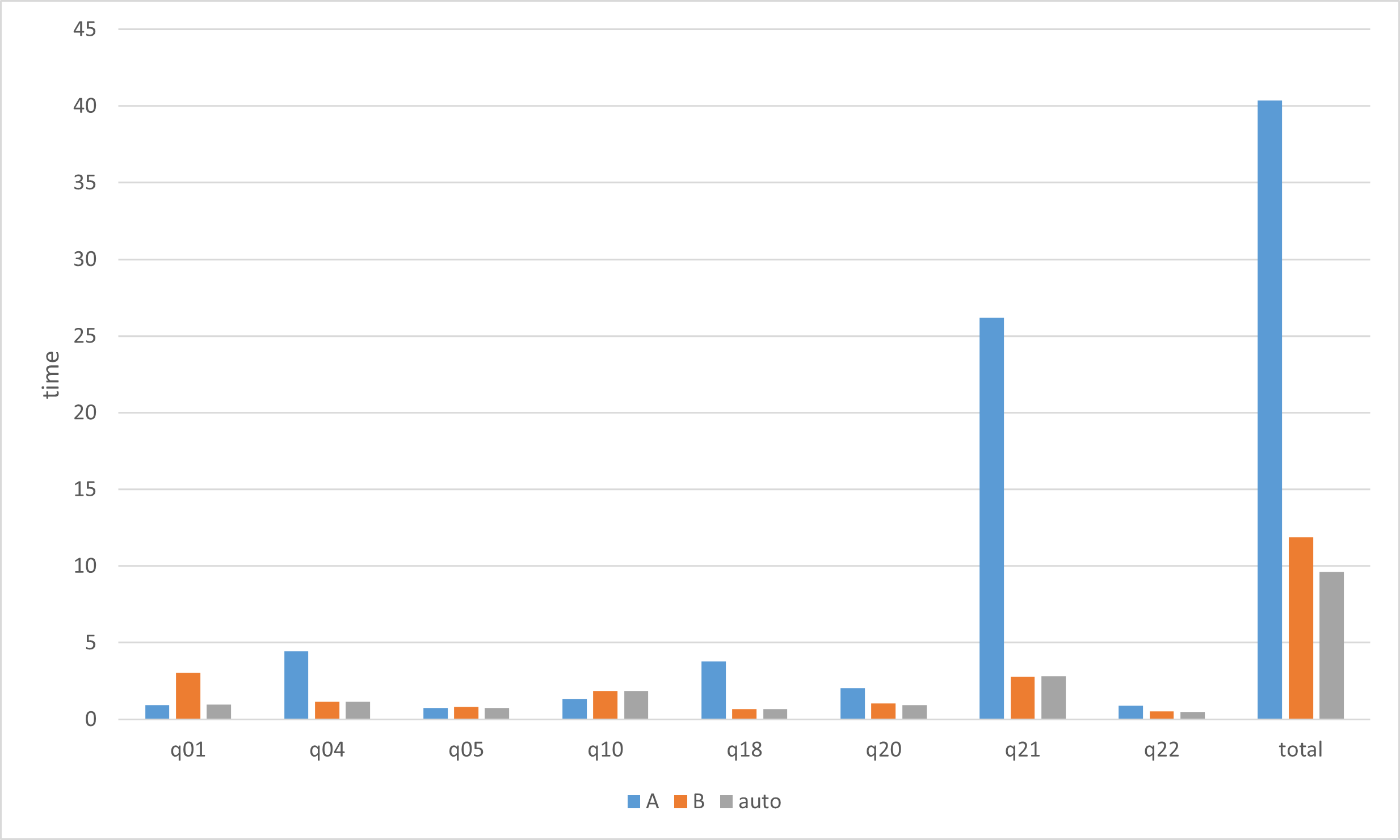
Aはgroupby操作をアルゴリズムAのみを用いており,Bはgroupby操作をアルゴリズムBのみを用いています. autoはgroupby操作についてグループ数の推定とアルゴリズムAとBの自動選択をしています. アルゴリズムAとアルゴリズムBの実行時間にほとんど差がない処理については上のグラフでは省略しています. グラフから,q10を除く処理で自動判定アルゴリズムは,アルゴリズムAとアルゴリズムBのうち速い方のアルゴリズムの選択ができていることが分かります. totalはアルゴリズムA,アルゴリズムB,自動選択アルゴリズムについて上記グラフから除いた処理も含めたTPC-H全体の計算時間を示しています. このことからTPC-H全体において,自動判定アルゴリズムはアルゴリズムAに対して3倍程度高速化ができており, アルゴリズムBに対しては1.2倍程度高速化ができていることが分かります.
参考
M. Bressan, E. Peserico, and L. Pretto. Simple set cardinality estimation through random sampling. CoRR, abs/1512.07901, 2015. ↩︎