実行モデル
FireDucksの実行モデルはpandasと異なります.pandasはメソッドが呼び出されると即座にその処理が実行されるEager実行モデルですが,FireDucksは結果が必要となったときにまとめて処理が実行される遅延実行モデルです.
遅延実行モデル
pandasとFireDucksの実行イメージは次の図のようになります.
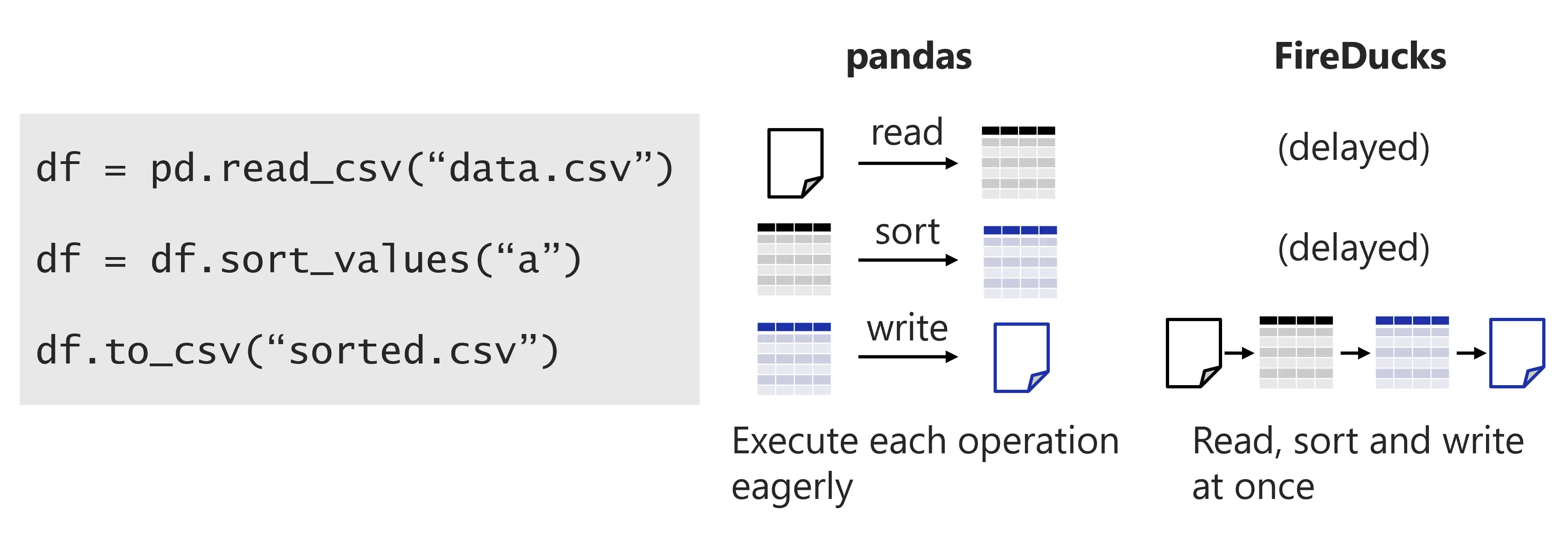
pandasでは,例えばread_csvメソッドを呼び出すとcsvファイルからデータが読み込まれます.一方,FireDucksではread_csvに相当する中間言語の生成が行われるだけで,データの実際の読み込みはまだ行われません.そのためFireDucksではdf = pd.read_csv("data.csv")と書かれている行の実行は即座に終わったように見えます.
このようにFireDucksのほとんどのメソッドは,実際のデータフレームの処理を行うことはなく中間言語の生成だけを行います.メソッドを呼び出す度にどんどん中間言語が生成されていき,結果が必要になったとき(例えばcsvファイルに書き出すとき)に,それまでに生成された中間言語を一気に実行します.
FireDucksで実際にデータフレームの処理が実行されるタイミングとしては以下のような場合があります.
- ファイルへの保存(
DataFrame.to_csvやDataFrame.to_parquet) - データフレームの表示(
print(df)など)
こういった実行モデルの違いがあるために,pandasに慣れている方にとっては,時間がかかるはずのメソッドが一瞬で終わったように見えたり,ファイルへの書き込みに普段より時間がかかるように感じられるかもしれません.
時間計測について
FireDucksでは遅延実行が行われるため,もしメソッド単位で実際の処理の時間を計測したい場合はちょっとした工夫が必要です.
例えば以下のように時間計測を行ったとしても,最後の計測区間(t3 - t2)にすべての処理の時間が含まれてしまいます.
t0 = time.time()
df = pd.read_csv("data.csv")
t1 = time.time()
df = df.sort_values("a")
t2 = time.time()
df.to_csv("sorted.csv")
t3 = time.time()
バージョン0.9.1から、この目的のためにベンチマークモードが導入されました。 ベンチマークモードが有効な場合、FireDucksはメソッドが呼び出された直後にそのメソッドを実行します。 これはFireDucksのいくつかの最適化を無効にするため、個々のメソッドを測定したい場合にのみ使用してください。
ベンチマークモードを有効にするには,以下のように環境変数を指定してください.
FIREDUCKS_FLAGS="--benchmark-mode"
以下のようにコード中から有効にすることも可能です.
from fireducks.core import get_fireducks_options
get_fireducks_options().set_benchmark_mode(True)
別の方法として,即座に処理を実行させるためのFireDucksの独自メソッド_evaluateを使うこともできます.
t0 = time.time()
df = pd.read_csv("data.csv")._evaluate()
t1 = time.time()
df = df.sort_values("a")._evaluate()
t2 = time.time()
df.to_csv("sorted.csv")._evaluate()
t3 = time.time()
ただし,このようにすると実行が細切れとなるため,FireDucksが複数の処理をまとめて最適化する機能が働きにくくなることに注意してください.そのため_evaluateの利用は個別のメソッドの時間計測を行う場合だけにしたほうが良いでしょう.